什么是比特币算力?如何监控矿机算力并提高矿场运营效率
比特币算力(Hashrate)衡量矿机或全网每秒能执行多少次哈希计算,算力越高找到新区块的概率越高。本文介绍算力的计算方式、影响因素,以及矿工如何通过监控与统一管理平台提升矿场运营效率。
前言
无论是在矿机参数页面、矿池后台,还是比特币行业新闻中,你都会频繁看到一个词 - Hashrate(算力)。例如:
- 比特币全网算力创下历史新高;
- 某型号 ASIC 矿机拥有 250 TH/s 算力;
- 某矿场总算力达到 20 PH/s。
对于刚接触比特币挖矿的人来说,这些数字往往令人困惑。
- 算力究竟是什么?
- 为什么算力越高,矿工获得区块奖励的概率越大?
- 矿机标称的 250 TH/s 是否意味着它会一直稳定运行在这个水平?
更重要的是,当矿机规模从几台增长到几十台、几百台甚至数千台时,如何持续监控这些算力,并确保它们真正转化为挖矿收益?
本文将从比特币算力的基本概念开始,系统介绍算力的计算方式、影响因素,以及矿工如何通过有效的监控和管理提升矿场运营效率。
什么是比特币算力?
比特币算力(Hashrate)是衡量比特币网络计算能力的核心指标。简单来说,算力代表矿机或整个比特币网络每秒能够执行多少次哈希计算。
比特币采用 SHA-256 哈希算法运行其工作量证明机制。矿工通过不断尝试不同的随机数,计算对应的哈希值,并寻找一个满足当前难度目标的结果。每一次尝试都需要完成一次哈希计算。因此算力越高,单位时间内能够进行的尝试次数越多,找到新区块的概率也越高。
根据中本聪在《Bitcoin: A Peer-to-Peer Electronic Cash System》中提出的设计,工作量证明机制正是通过这种持续消耗计算资源的方式来保护网络安全。
比特币算力是如何计算的?
由于比特币网络每秒执行的哈希计算数量极其庞大,人们通常不会直接使用 H/s 来描述算力,而是采用更大的计量单位。常见单位包括:
| 单位 | 含义 |
|---|---|
| KH/s | 千哈希每秒 |
| MH/s | 百万哈希每秒 |
| GH/s | 十亿哈希每秒 |
| TH/s | 万亿哈希每秒 |
| PH/s | 千万亿哈希每秒 |
| EH/s | 百京哈希每秒 |
目前单台 ASIC 矿机通常使用 TH/s 表示。例如 Bitmain Antminer S21 系列矿机的算力约为 200~300 TH/s。而矿场规模则通常使用 PH/s 表示。至于整个比特币网络,则已经进入 EH/s 时代。根据 Nonce 和 Hashrate Index 的统计数据,比特币全网算力近年来长期保持在数百 EH/s 的水平,并持续刷新历史记录。
需要注意的是,算力本身并不是一种「速度」。它实际上是每秒能够完成的哈希计算次数。因此,250 TH/s 的矿机意味着它每秒能够执行约 250 万亿次 SHA-256 哈希计算。
为什么比特币算力如此重要?
对于矿工来说,算力直接影响获得区块奖励的概率。对于整个网络来说,算力则决定了比特币系统的安全性。在工作量证明机制下,矿工之间不断竞争新区块。如果一台矿机拥有更高算力,它在同样时间内能够完成更多计算,因此获得新区块奖励的机会也更高。
与此同时,全网总算力越高,攻击比特币网络所需的成本也越高。这也是为什么行业经常把算力视为衡量网络健康程度的重要指标。
当新闻媒体报道,比特币算力创历史新高,实际上意味着,更多矿工正在投入资源参与网络运行。从长期来看,这通常反映出矿工对于比特币生态系统的持续投入与信心。根据 Macromicro 数据展示,比特币全网算力在 2025 年 10 月 11 日达到史上最高算力 1102245923.98T ,截止本文撰写时,全网算力 为 842716008.15T,下降了约 23.5%,这与比特币下跌有直接关系,也反馈了市场信心在随着比特币的下跌而下降。
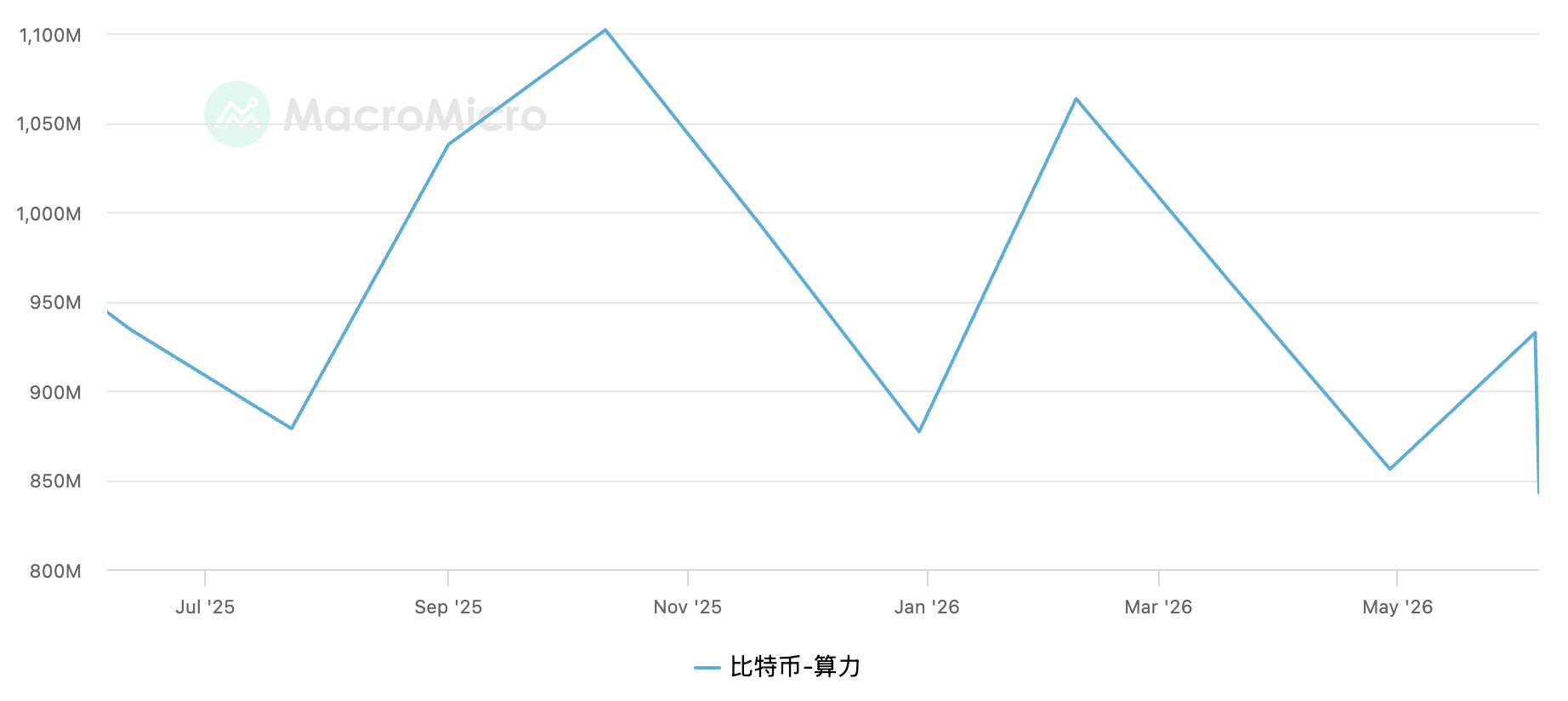
算力不仅与矿工收益有关。它还是比特币安全模型的重要组成部分。理论上,如果某个实体控制了超过全网一半的算力,就有能力发动所谓的 **51%攻击。**在这种情况下,攻击者可能重组部分区块、阻止部分交易确认、实施双花攻击。然而现实中,要获得足以攻击比特币网络的算力需要极其庞大的硬件和能源投入。
目前,比特币网络拥有全球最大的去中心化计算网络之一。任何试图获取足够算力发动攻击的行为,都需要承担极高的经济成本。同时攻击成功本身还可能导致市场信心下降和比特币价格下跌。因此,对于绝大多数参与者而言,诚实挖矿远比攻击网络更符合经济利益。这也是工作量证明机制能够长期保持安全性的根本原因之一。
哪些因素会影响矿机算力?
许多新矿工认为矿机的算力是固定的,实际上并非如此。矿机标称算力只是实验室环境下的参考值。在真实运行环境中,算力会受到多种因素影响。最常见的影响因素包括:
- 比特币价格
- 挖矿难度
- 哈希价格
- ASIC 硬件性能
- 电力成本
- 网络连接质量
- 温度与散热环境
- 固件配置
其中,对于单台矿机来说,温度、网络和设备状态往往是最直接的影响因素。而对于整个矿场来说,比特币价格与挖矿难度则会决定整体盈利能力。理解这些因素,是理解矿场运营的第一步。
为什么矿机标称算力与实际算力不同?
很多矿工在购买 ASIC 矿机之后都会遇到一个问题:矿机官方参数明明写着 250 TH/s,但矿池后台看到的实际算力却只有 230 TH/s 甚至更低。这是否意味着矿机出现故障?
答案是,不一定!事实上,矿机标称算力和实际算力之间出现一定差异是行业中的正常现象。因为矿机运行过程中受到许多因素影响。
温度过高导致降频
温度是影响 ASIC 性能最常见的因素之一。为了保护芯片安全,大多数 ASIC 矿机会在温度过高时自动降低频率。这种机制通常被称为热降频。当芯片温度持续升高时,矿机会主动降低算力输出,从而减少功耗和发热。对于矿工而言,结果通常表现为算力下降、收益下降、能效降低。因此温度监控始终是矿场运营中的核心工作之一。
网络质量影响有效算力
矿池统计的并不是矿机本地显示的理论算力。矿池统计的是矿机实际提交的有效计算部分。因此即使矿机本地显示 250 TH/s,矿池看到的有效算力也可能更低。造成这种情况的原因包括:
- 网络延迟;
- 丢包;
- DNS 问题;
- 路由配置异常;
- 矿池连接不稳定。
在大型矿场中,网络问题往往比硬件问题更容易被忽视。
固件配置问题
现代 ASIC 矿机通常支持标准模式、节能模式和超频模式。不同模式下算力表现会明显不同。此外矿池配置错误、频率参数异常、错误的固件版本,都可能导致矿机无法发挥正常性能。
矿机老化与硬件故障
随着运行时间增加,ASIC 设备不可避免地会出现老化。例如 Hashboard 故障、风扇损坏、电源异常、芯片失效等,这些问题通常不会导致矿机立即离线。更常见的情况是矿机仍然在线,但算力持续下降。如果缺乏监控系统,运营团队往往难以及时发现。
如何监控矿机算力?
对于只有几台矿机的矿工来说,查看算力非常简单。登录矿池后台即可。但随着矿机数量增长,问题开始变得复杂。运营团队不仅需要知道哪台矿机在线,更需要知道哪台矿机正在创造收益。因此,现代矿场通常会持续监控以下关键指标。
实时算力
实时算力反映矿机当前的运行状态。它能够帮助运营人员快速发现掉线设备、降频设备和性能异常设备。不过,实时算力天然存在波动。
因此,专业矿工通常会同时观察 15 分钟平均算力,1 小时平均算力 和 24 小时平均算力。而不是单纯依赖瞬时数据。
矿池算力
矿池算力通常更接近真实收益表现。因为矿池看到的是矿工提交的有效工作量。如果发现矿机本地算力正常,但矿池算力长期偏低,通常意味着网络问题、拒绝率偏高、矿池连接异常。
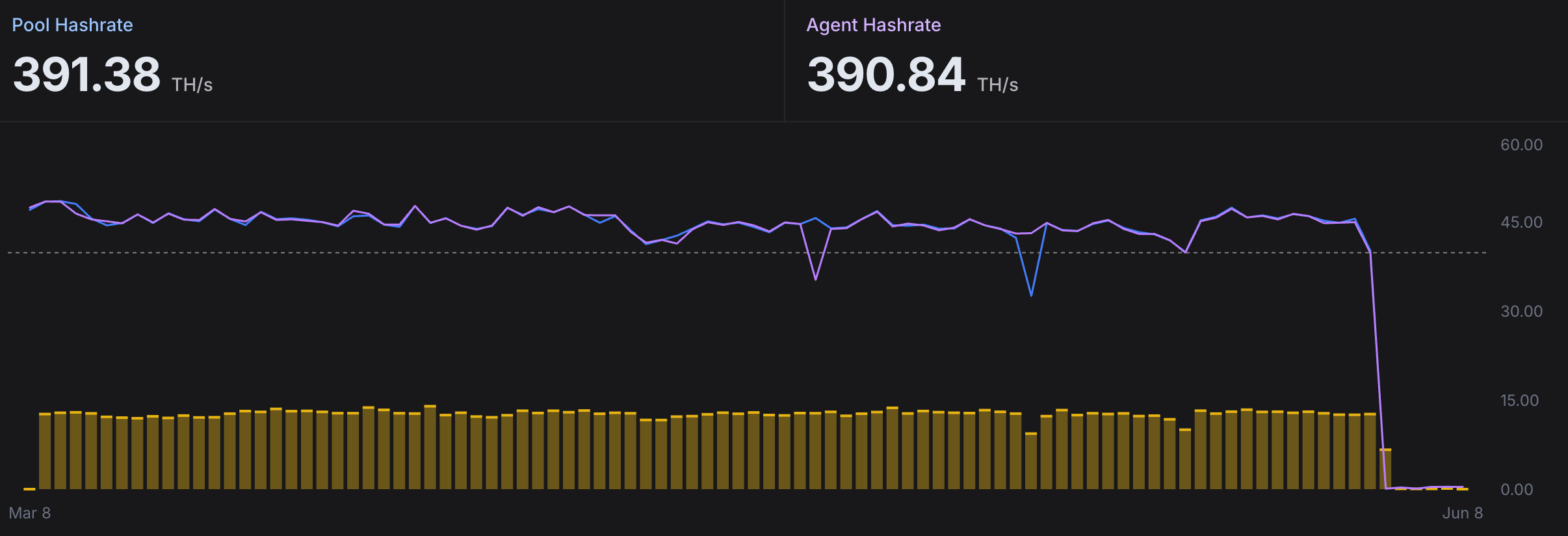
拒绝率
拒绝率是很多矿工容易忽视的指标。它表示矿池拒绝接受的 Shares 占比。拒绝率过高意味着矿机虽然在运行,但部分计算结果无法产生收益。造成拒绝率增高的常见原因包括网络延迟、矿池问题、时钟同步异常、固件错误等。
温度与功耗
除了算力之外,专业矿场通常还会持续监控芯片温度、环境温度、功耗、风扇转速。温度异常往往早于故障发生,很多设备问题在算力下降之前,就已经反映在温度数据中。
为什么矿场需要统一管理矿机?
对于拥有几台矿机的矿工来说,人工管理并不是问题。但当矿机数量增长到成百上千台的时候,情况会完全不同。此时运营团队每天都需要处理诸如掉线设备、算力异常、固件升级、网络故障、温度告警、矿池配置变更等问题。
如果仍然依靠 Excel 表格、人工巡检、矿池后台进行管理,那么运营效率会迅速下降。很多矿场真正的损失并非来自设备故障,而是设备已经出现问题,但运营团队没有及时发现。所以,现代矿场越来越倾向于使用统一管理平台,来集中监控 ASIC 设备的算力表现、在线状态、温度数据和告警事件等,从而减少人工巡检时间,并提高设备在线率和整体运营效率。
优秀的矿场管理平台应该具备哪些能力?
对于现代比特币矿场来说,管理软件已经逐渐从辅助工具演变为核心基础设施。过去几年里,ASIC 矿机性能持续提升,单个矿场管理的设备数量也在不断增长。与此同时,矿场运营团队面临的挑战不再只是设备采购和电力成本。越来越多的运营问题开始集中在设备监控、运维效率、故障响应、团队协作和数据管理。因此,选择合适的矿场管理平台已经成为矿场运营的重要决策之一。
那么,一套优秀的矿场管理平台应该具备哪些能力呢?
自动发现与资产管理
对于大型矿场而言,第一步往往不是监控,而是知道自己究竟拥有多少设备。现实中,许多矿场会持续新增设备、更换设备或迁移设备。如果依赖人工登记,资产信息很容易失真。因此,优秀的平台通常具备自动发现能力。能够自动扫描网络中的 ASIC 设备,并建立统一资产库。运营团队可以快速查看矿机型号、IP 地址、固件版本、所属矿场、在线状态等,从而降低设备管理成本。
实时监控与警报
监控是矿场管理平台最基础的能力,但真正有价值的监控并不仅仅是展示数据。更重要的是,在异常发生时及时通知运营团队。例如,当出现矿机掉线、算力下降、温度异常、拒绝率升高、矿池连接失败,系统应该能够主动触发告警。
相比人工巡检,自动告警能够显著缩短故障发现时间。对于大型矿场来说,故障发现速度往往直接影响收益损失。
批量操作能力
随着矿机规模扩大,批量操作能力的重要性会迅速提升。例如运营团队可能需要同时完成:
- 修改矿池配置;
- 批量升级固件;
- 批量重启设备;
- 调整频率参数;
- 更新网络配置;
如果逐台处理,即使只是简单操作,也可能耗费数小时。因此批量管理已经成为现代矿场软件的基础能力之一。
多矿场与多团队协作
随着矿场规模扩大,许多运营团队开始管理多个站点。这些站点可能分布在全球各个区域。此时运营团队需要统一查看算力表现、设备状态、告警信息、运维记录等信息,而不是在多个系统之间切换。
同时,不同团队成员通常承担不同职责。因此,权限管理与协作能力也逐渐成为企业级矿场的重要需求。
API 与自动化能力
近年来,矿场运营逐渐走向自动化。越来越多团队开始通过 API、Webhook、自动化脚本和 AI Agent 构建自己的运营流程。例如,当矿机掉线时自动创建工单,当温度异常时自动通知值班人员,当矿池连接失败时自动切换备用矿池。
因此,开放 API 已经成为现代矿场管理平台的重要组成部分。
为什么 ASIC Monitoring 正在成为矿场基础设施?
十年前,矿工最关心的问题是:如何获得更多算力。而今天,越来越多矿场开始关注如何保证已有算力持续在线。
在成熟市场中,收益增长越来越依赖运营效率。如果一个拥有 5 EH/s 管理规模的矿场,能够将平均故障发现时间从 2 小时缩短到 15 分钟。长期来看,其收益提升可能远高于采购额外设备带来的增益。因此 ASIC Monitoring 已经不再只是监控工具。它正在成为矿场运营体系的重要组成部分。运营团队越来越关注:
- 在线率
- 平均故障恢复时间
- 告警响应速度
- 运维效率
而不仅仅是单纯的算力数字。
Nonce 如何帮助矿场提高运营效率?
正如前文所言,对于运营团队而言,管理矿场的目标从来不仅仅是查看数据。真正重要的是:让更多设备保持在线,并尽可能减少人为操作成本。
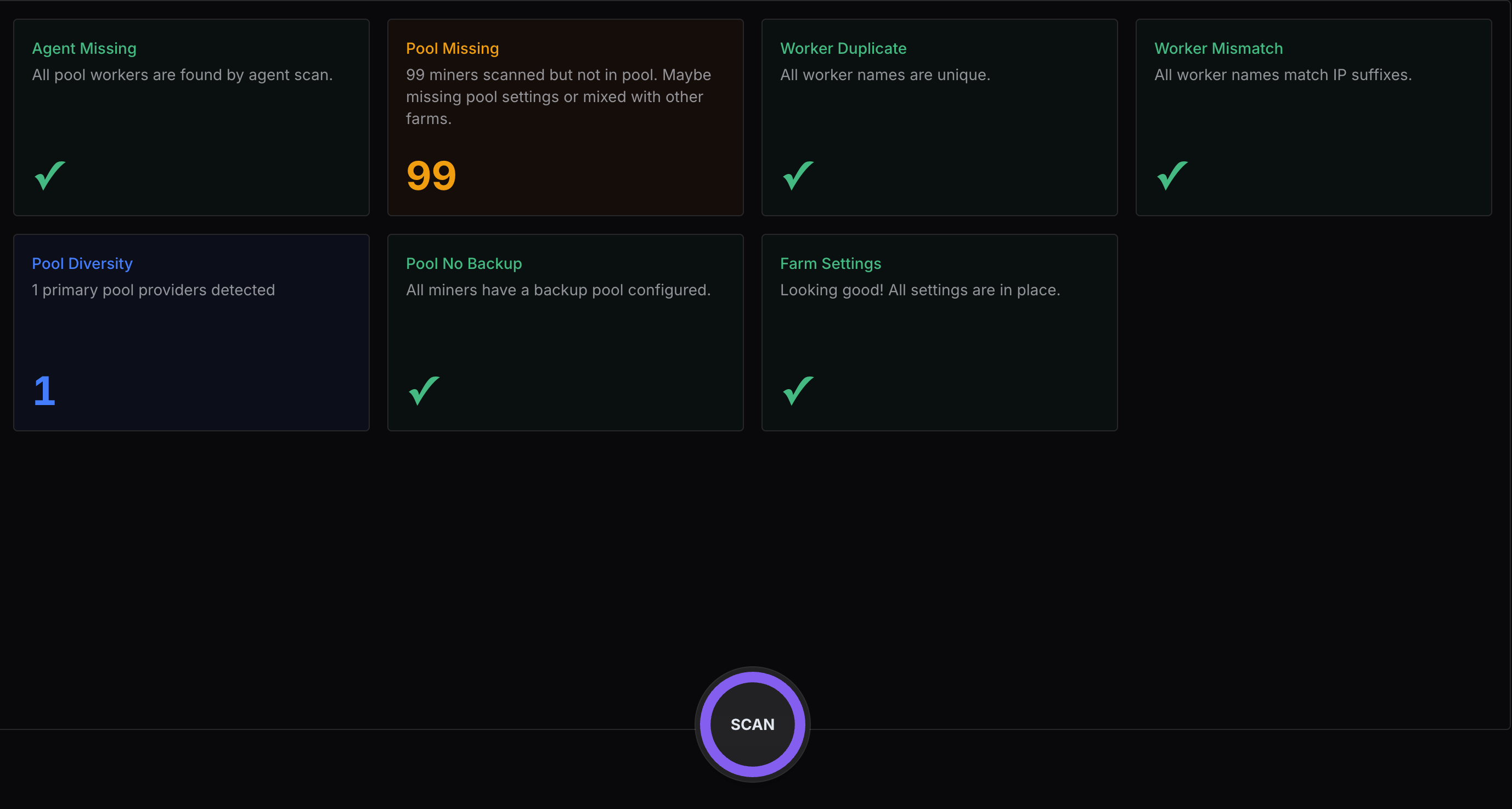
Nonce 是一个面向现代比特币矿场的管理平台,旨在帮助运营团队统一监控、管理和优化 ASIC 设备。Nonce 提供包括:
- 自动发现矿机
- ASIC 监控
- 实时告警
- 批量操作
- 固件管理
- 多矿场管理
- API 集成
- AI Agent 能力
在内的一系列功能。相比在多个系统之间切换,运营团队能够在统一平台中查看:
- 设备状态
- 算力表现
- 在线情况
- 告警事件
- 运维操作记录
从而更快发现问题并提高响应效率。对于拥有几十台设备的矿工来说,这些能力意味着更少的人工检查。而对于拥有数百台甚至数千台设备的矿场来说,则意味着更高的运营效率和更好的规模化管理能力。